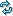0
IOTA
IOTA架构是基于iota和AI时代背景下的大数据架构模式,其整体技术结构的核心是贯穿于整体业务始终的数据模型,具有提高整体的预算效率的作用。IOTA架构这一概念由易观首次提出,并将其应用于最新研发的精细化运营工具中。
Common Data Model
贯穿整体业务始终的数据模型,这个模型是整个业务的核心,要保持SDK、cache、历史数据、查询引擎保持一致。对于用户数据分析来讲可以定义为“主-谓-宾”或者“对象-事件”这样的抽象模型来满足各种各样的查询。以大家熟悉的APP用户模型为例,用“主-谓-宾”模型描述就是“X用户–事件1 – A页面(2018/4/11 20:00)”。当然,根据业务需求的不同,也可以使用“产品-事件”、“地点-时间”模型等等。模型本身也可以根据协议(例如protobuf)来实现SDK端定义,中央存储的方式。此处核心是,从SDK到存储到处理是统一的一个Common Data Model。
Edge SDKs & Edge Servers
这是数据的采集端,不仅仅是过去的简单的SDK,在复杂的计算情况下,会赋予SDK更复杂的计算,在设备端就转化为形成统一的数据模型来进行传送。例如对于智能Wi-Fi采集的数据,从AC端就变为“X用户的MAC地址-出现- A楼层(2018/4/11 18:00)”这种主-谓-宾结构,对于摄像头会通过Edge AI Server,转化成为“X的Face特征-进入- A火车站(2018/4/11 20:00)”。也可以是上面提到的简单的APP或者页面级别的“X用户–事件1 – A页面(2018/4/11 20:00)”,对于APP和H5页面来讲,没有计算工作量,只要求埋点格式即可。
Real Time Data
实时数据缓存区,这部分是为了达到实时计算的目的,数据接收不可能实时入历史数据库,那样会出现建立索引延迟、历史数据碎片文件等问题。因此,有一个实时数据缓存区来存储最近几分钟或者几秒钟的数据。这块可以使用Kudu或者Hbase等组件来实现。这部分数据会通过Dumper来合并到历史数据当中。此处的数据模型和SDK端数据模型是保持一致的,都是Common Data Model,例如“主-谓-宾”模型。
Historical Data
历史数据沉浸区,这部分是保存了大量的历史数据,为了实现Ad-hoc查询,将自动建立相关索引提高整体历史数据查询效率,从而实现秒级复杂查询百亿条数据的反馈。例如可以使用HDFS存储历史数据,此处的数据模型依然SDK端数据模型是保持一致的Common Data Model。
Dumper
Dumper的主要工作就是把最近几秒或者几分钟的实时数据,根据汇聚规则、建立索引,存储到历史存储结构当中,可以使用map reduce、C、Scala来撰写,把相关的数据从Realtime Data区写入Historical Data区。
Query Engine
查询引擎,提供统一的对外查询接口和协议(例如SQLJDBC),把Realtime Data和Historical Data合并到一起查询,从而实现对于数据实时的Ad-hoc查询。例如常见的计算引擎可以使用presto、impala、clickhouse等。
Realtime model feedback
通过Edge computing技术,在边缘端有更多的交互可以做,可以通过在Realtime Data去设定规则来对EdgeSDK端进行控制,例如,数据上传的频次降低、语音控制的迅速反馈,某些条件和规则的触发等等。简单的事件处理,将通过本地的IOT端完成,例如,嫌疑犯的识别已经有很多摄像头本身带有此功能。
去ETL化
ETL和相关开发一直是大数据处理的痛点,IOTA架构通过Common Data Model的设计,专注在某一个具体领域的数据计算,从而可以从SDK端开始计算,中央端只做采集、建立索引和查询,提高整体数据分析的效率。
Ad-hoc即时查询
鉴于整体的计算流程机制,在手机端、智能IOT事件发生之时,就可以直接传送到云端进入real time data区,可以被前端的Query Engine来查询。此时用户可以使用各种各样的查询,直接查到前几秒发生的事件,而不用在等待ETL或者Streaming的数据研发和处理。
边缘计算(Edge-Computing)
将过去统一到中央进行整体计算,分散到数据产生、存储和查询端,数据产生既符合Common Data Model。同时,也给与Realtime model feedback,让客户端传送数据的同时马上进行反馈,而不需要所有事件都要到中央端处理之后再进行下发。